Python Post Processing
Description
This document describes how to use the Python Post processing section on your model.
(If you've come to this document looking on how to use the Python Blocks in Workflows, we will be releasing a guide for that very soon!)
Introduction
The Python Post processing feature is very useful when you want to change/add/edit the data extracted from your document that requires more complex logic.
Here are a few examples
- Adding a new label to the extracted data
- Altering the text of a label
- Changing the text in a column
- Adding a new column to a table
- Setting a validation on an extracted label
- Changing the filename
- And a lot more!
Note: You can do all of the above from the Workflows section as well. This feature helps if the logic to do these things is more complex than we currently support.
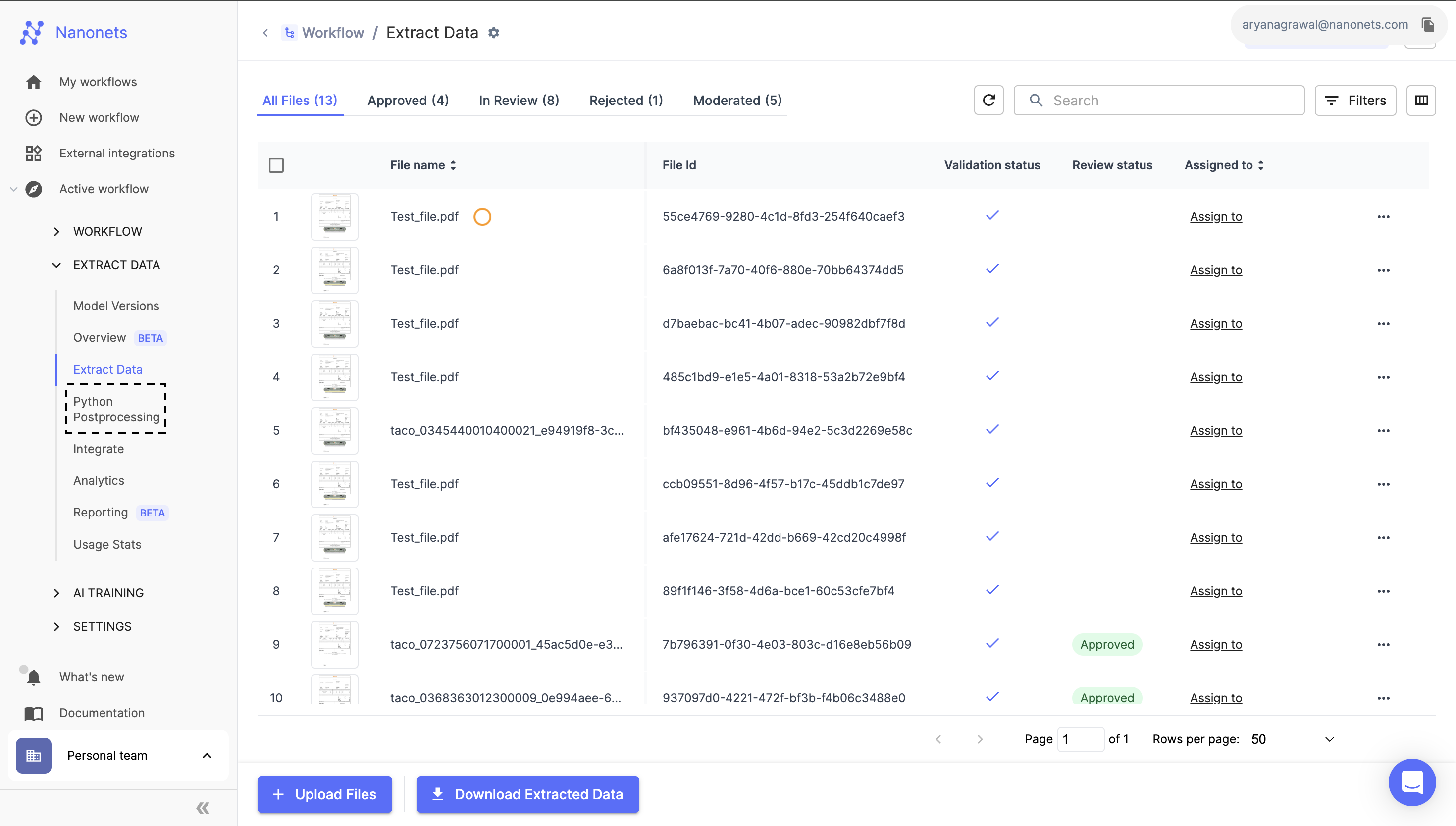
You can navigate to the Python Post processing section by heading over to https://app.nanonets.com/#/ocr/postprocess/<MY_MODEL_ID>
When you first open the section, you'll see a very simple handler function defined
Pattern of execution
After the data has been extracted from your uploaded document and the workflows section has run, this handler function is called. So here is the pattern of execution:
- Document uploaded
- Data extracted from document by model
- Data Action from Workflows runs on data from step #2
- Approvals/Validations from Workflows runs on data from step #3
- Python Post processing runs on data from step #4
When you use the rerun workflow feature, the same pattern of execution happens excluding steps #1 and #2. However this time, the data into step #3 comes from the data that is already present in the document.
Note: We will always call the function called "handler". It has a single input and a single output.
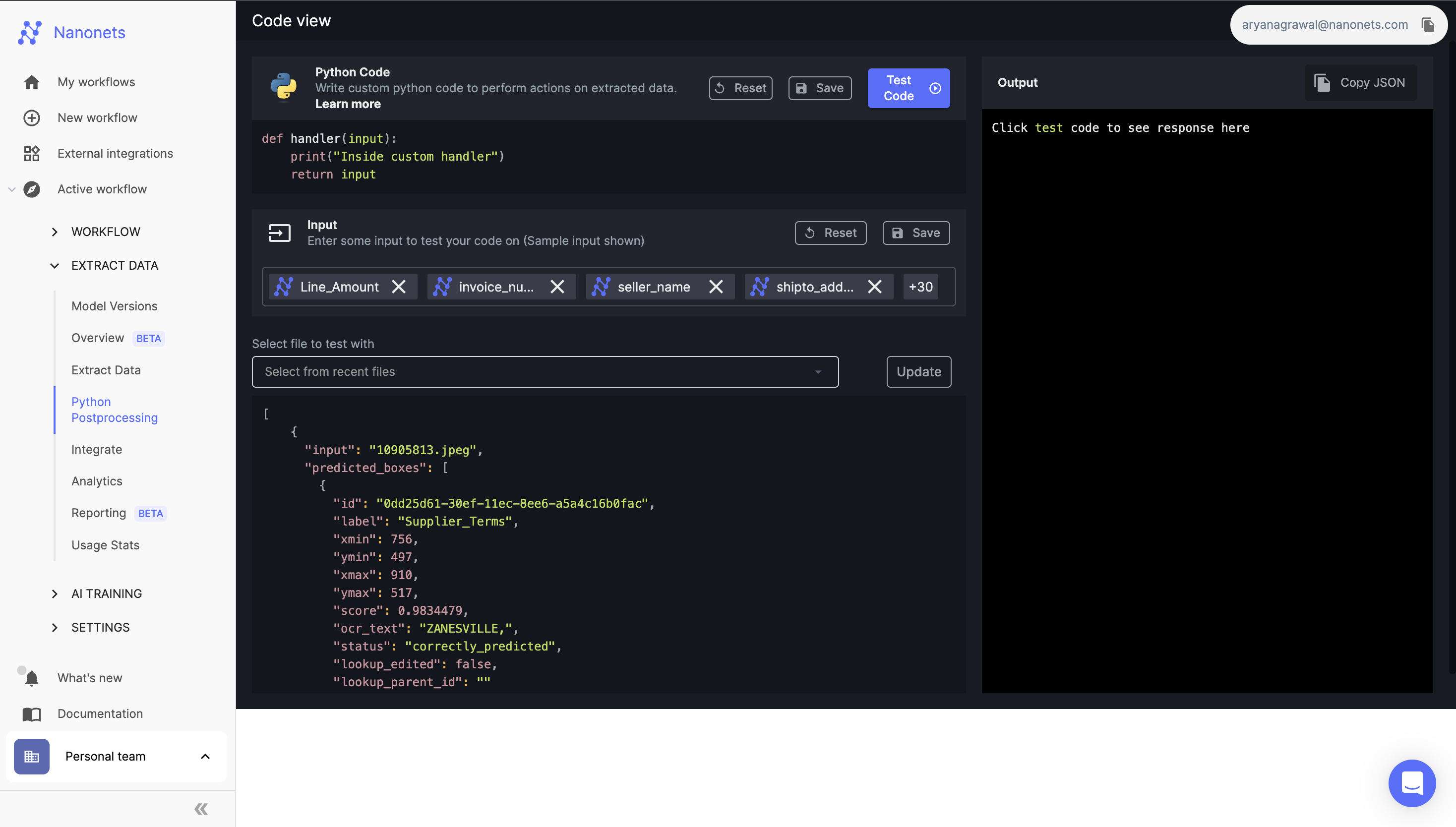
Inputs and Outputs
Now let's come to the input and outputs.
Input
The inputs to this function is a JSON object of the data extracted from the document after the data actions and validations have run from the workflows section.
What does it look like?
20000 ft view
[
{data from page 0},
{data from page 1},
{data from page 2}
]Note: The page numbering starts from 0 here. On the Extract Data section on the UI, the page numbering starts from 1.
500 ft view
[
{
"input": "10905813.jpeg",
"predicted_boxes": [{
"id": "0dd25d61-30ef-11ec-8ee6-a5a4c16b0fac",
"label": "Supplier_Terms",
"xmin": 756,
"ymin": 497,
"xmax": 910,
"ymax": 517,
"score": 0.9834479,
"ocr_text": "ZANESVILLE,",
"status": "correctly_predicted"
},
{data from box 2},
{data from box 3},
{data from box 4},
],
"moderated_boxes" : [structure is same as predicted_boxes],
"prediction" : [structure is same as predicted_boxes],
"raw_ocr" : [structure is same as predicted_boxes],
"custom_response": null,
"page": 0,
"day_since_epoch": 18919,
"hour_of_day": 15,
"request_file_id": "d9fbc6d5-61d2-4c5a-8787-113a4069d5dc",
"filepath": "uploadedfiles/a5665dfd-3619-4d35-8fec-694db39c5a77/PredictionImages/1376246724.jpeg",
"id": "94d8be28-30ee-11ec-9956-0242ac120004",
"is_moderated": false,
"rotation": 0,
"updated_at": "331196ba-30ef-11ec-99fa-0242ac120004"
"request_metadata": "contains data sent in metadata or the email information if enabled from model settinsg",
"size" : ["width" : 450, "height": 900],
"original_file_name" : "1234.pdf",
"rotation" : 0
},
{data from page 1},
{data from page 2}
]The data extracted for each page is available in predicted_boxes and moderated_boxes. Why do we have 2 places where the data is stored? good question, we'll address this after describing the output
Output
The structure of the output from the handler function has to be the same as the input. However everything inside the input can be changed.
For eg: to change the uploaded file name, you can write code to edit the original_file_name key in the input.
Why is the extracted data present in 2 places?
This is done so that we can differentiate between the data extracted from the document and the data that was altered due to moderation.
Initially after a document is uploaded, the moderated_boxes array will be empty. The data extracted from the document will be in the predicted_boxes key. The moment any moderation or change is done on a document, then the moderated_boxes key will contain all the data from the document.
In order to change the data on the UI, you should always check if the moderated_boxes array is empty or has data present. If it's empty then use you can alter the data in the predicted_boxes array, if it has data then you can alter the data in the moderated_boxes array. Essentially
def handler(input):
//iterating over pages
for page in input:
//find which data we need to change
data_to_change = page["predicted_boxes"]
if "moderated_boxes" in page and len(page["moderated_boxes"]) > 0:
data_to_change = page["moderated_boxes"]
//do something with data_to_change
for predictions in data_to_change:
do something
return inputExamples
Now that we have the overall definitions and nuances out of the way, let's get into some examples that makes this feature easier to understand
Updated about 1 year ago