On Prem Offerings
- What is our on-premises solution:
In the on-prem solution, customers can run our Deep Learning model on their own premises using our docker images. This creates a version of our API that is hosted on our customers' own servers.
Now, if you are unclear regarding what a docker is, we have you covered.
A docker is a set of platform as a service products that use OS-level virtualization to deliver software in packages called containers. Containers are isolated from one another and bundle their own software, libraries and configuration files; they can communicate with each other through well-defined channels.
A key pointer to note here is that customers retain their data since the storage occurs on their servers in an on-premises solution, and Nanonets doesn't store any data.
- Hardware requirements overview:
Detailed hardware requirements can be found at the end of this document.
- 8 cpu, 32 GB (2 instances)
- 4 cpu, 16 GB, 1GPU (3 instances)
- On demand we need 1 instance of 4cpu, 16GB, 1GPU only used while training
- 450 GB storage
This is the recommended hardware, for any modifications to the following, please feel free to get in touch with our activation team.
- Supported features in an on-premises solution:
- New model building and retraining
- API support for file upload and model prediction
- Pre trained models
- Usage Statistics
- SSO
- Workflows*
- Post processing
- Architectural diagram:
The Standard NanoNets docker architecture diagram looks like the one below. It makes network requests for 3 purposes -
-
To fetch the docker image -This is required only during the installation phase.
-
To perform validity license checks - This happens frequently and is done to validate the expiry time of the contract. During this process, no data gets transferred to Nanonets Servers.
-
To extract the raw OCR text present on the image(pdf) - Since this is the customer's choice of OCR, the customer can decide to keep this within their network/region and no data gets transferred to Nanonets.
You can refer to Data Privacy of AWS Textract from here and Google Vision from here
Users can choose between the OCR engine of their choice: Amazon Textract or Google vision
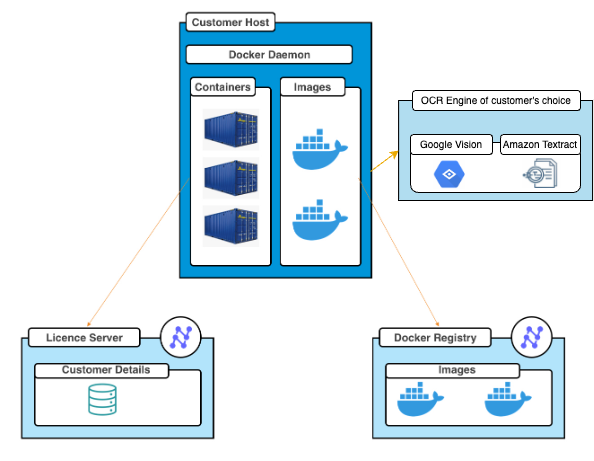
Architecture diagrams for specific use-cases may vary slightly.
- Hardware requirements detailed:
Option 1: Cluster
The following hardware is the minimum recommended requirement for on-prem deployment:
- 8-core CPU, 32GB ram instance (2 PODS)
- API service, Database
- AWS equivalent: t3.2xlarge (500 USD/month)
- API service, Database
- 4-core CPU, 16GB RAM, 16GB GPU memory with cuda compatible GPU (3 PODS min)
- Embedding service
- Compatible GPU's - https://developer.nvidia.com/cuda-gpus
- AWS equivalent: g4dn.xlarge (1150 USD/month)
- (On demand) 4-core CPU, 16GB RAM, 16GB GPU memory with cuda compatible GPU (1 POD min)
- Worker Service (this can be switched off whenever model is not being trained)
- Compatible GPU's - https://developer.nvidia.com/cuda-gpus
- AWS equivalent: g4dn.xlarge. (190 USD/month, assuming this is active for 15 days)
- If using kubernetes, this is required only on demand as k8s job when training is triggered
- Distributed Storage service
- AWS equivalent - S3, EFS (450 GB; 135 USD/month)
- GCP Equivalent - Google Files Store
- (Optional) Kubernetes cluster
- AWS equivalent: EKS
- (Optional) Docker registry
- AWS equivalent: ECR
Option 2. Prediction Docker
- Option 2. Prediction Docker
- 4-core CPU, 16GB RAM
*Few flows might not be supported on-prem because of Infrastructure limitations.
*PODs can be increased based on load and latency req. For this, feel free to reach out to your Activation/CS manager.
*Workflow features aren't supported in option 2(Prediction docker)
Updated about 1 year ago