Instant Learning Model Training and Best Practices
Overview
This is a type of model that learns quickly from each file you upload on the Nanonets and approve, so you don't have to wait a long time to see improvements based on your feedback. With instant learning models, the learning process is immediate, ensuring that the model rapidly adjusts to new data and insights. The instant learning model only learns from modified images that are approved. Be sure to approve files in order for the model to learn from the changes.
What is the difference between Fields and Table Headers?
- Fields: When defining a field, it is assumed that on a given page or within a specific document, the field will have a singular value.
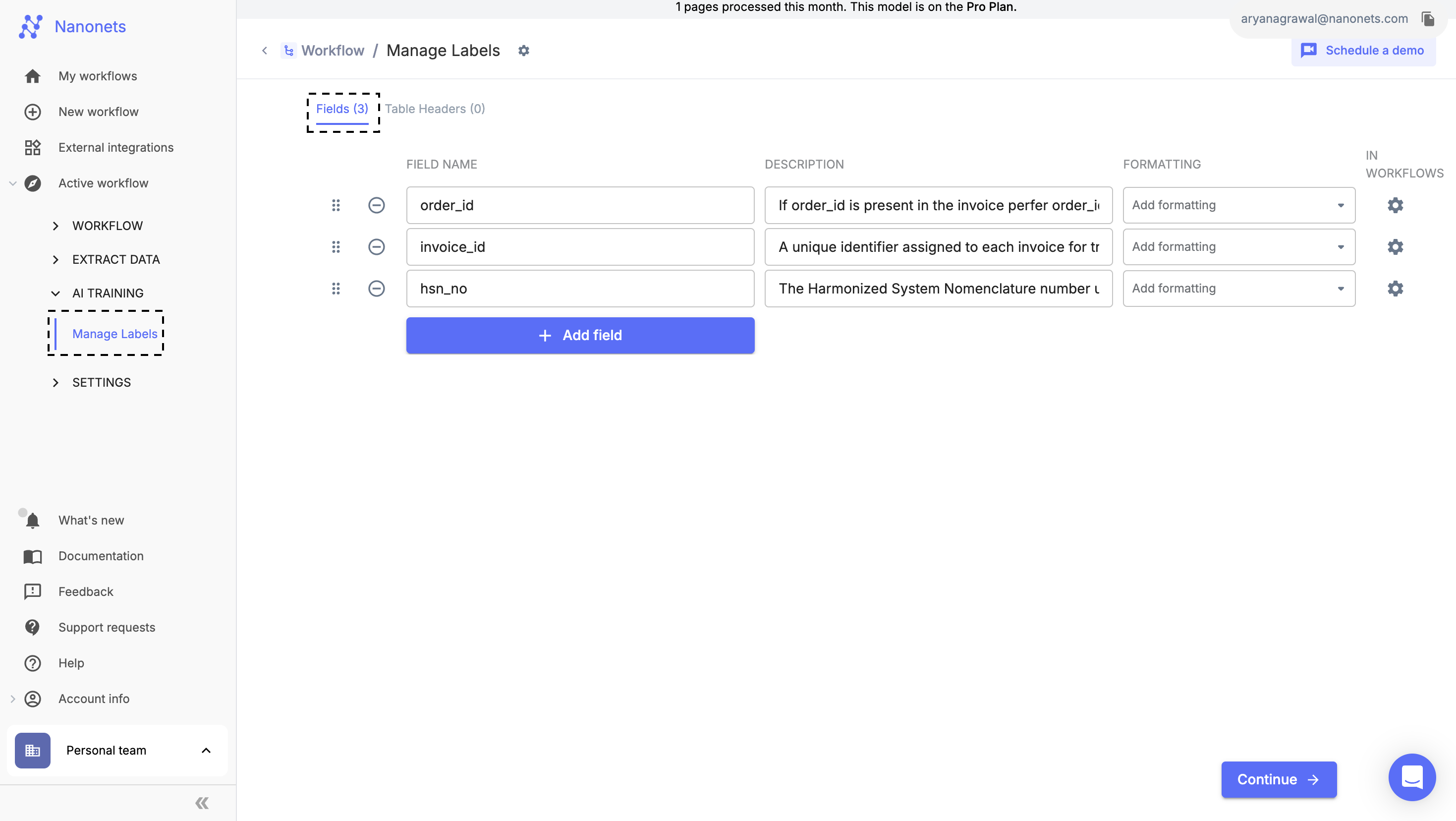
Fields Section
- Table Headers: When defining a table header, it is possible that multiple values for a single field can exist per page or document.
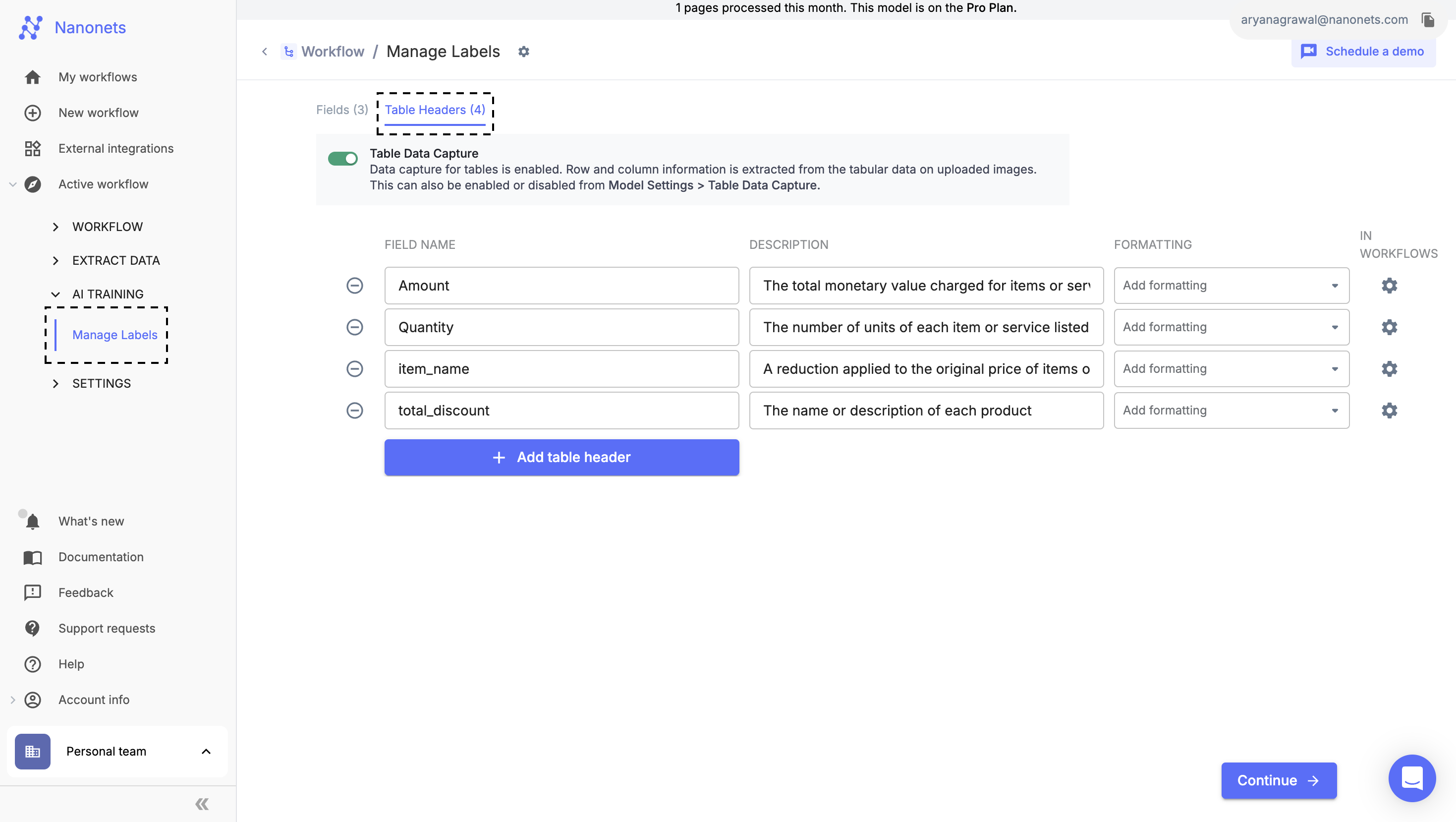
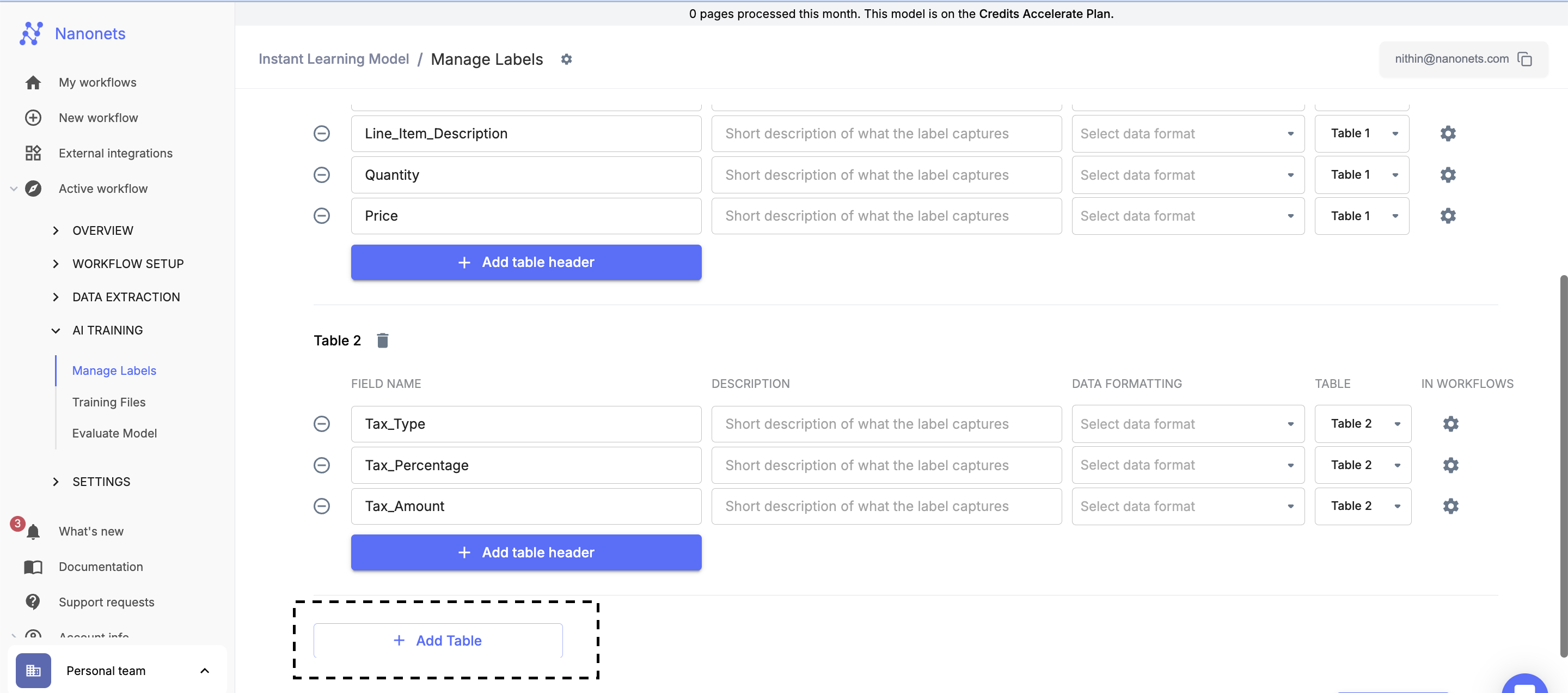
- Multiple Tables It is possible to create multiple Tables for extraction and define labels for each table by using Add Table Button
Training Steps:
1. Correct Mistakes in Fields and Tables
- Post-Upload Processing: After uploading a file, navigate to the extracted data to review and make corrections.
- Adjustments and Corrections: Adjust the boundaries of annotated boxes to capture text accurately. Modify any incorrect predictions and finalize by saving the changes.
- Saving Changes: Confirm all modifications by clicking the "Save" button, which applies the corrections and updates the dataset.
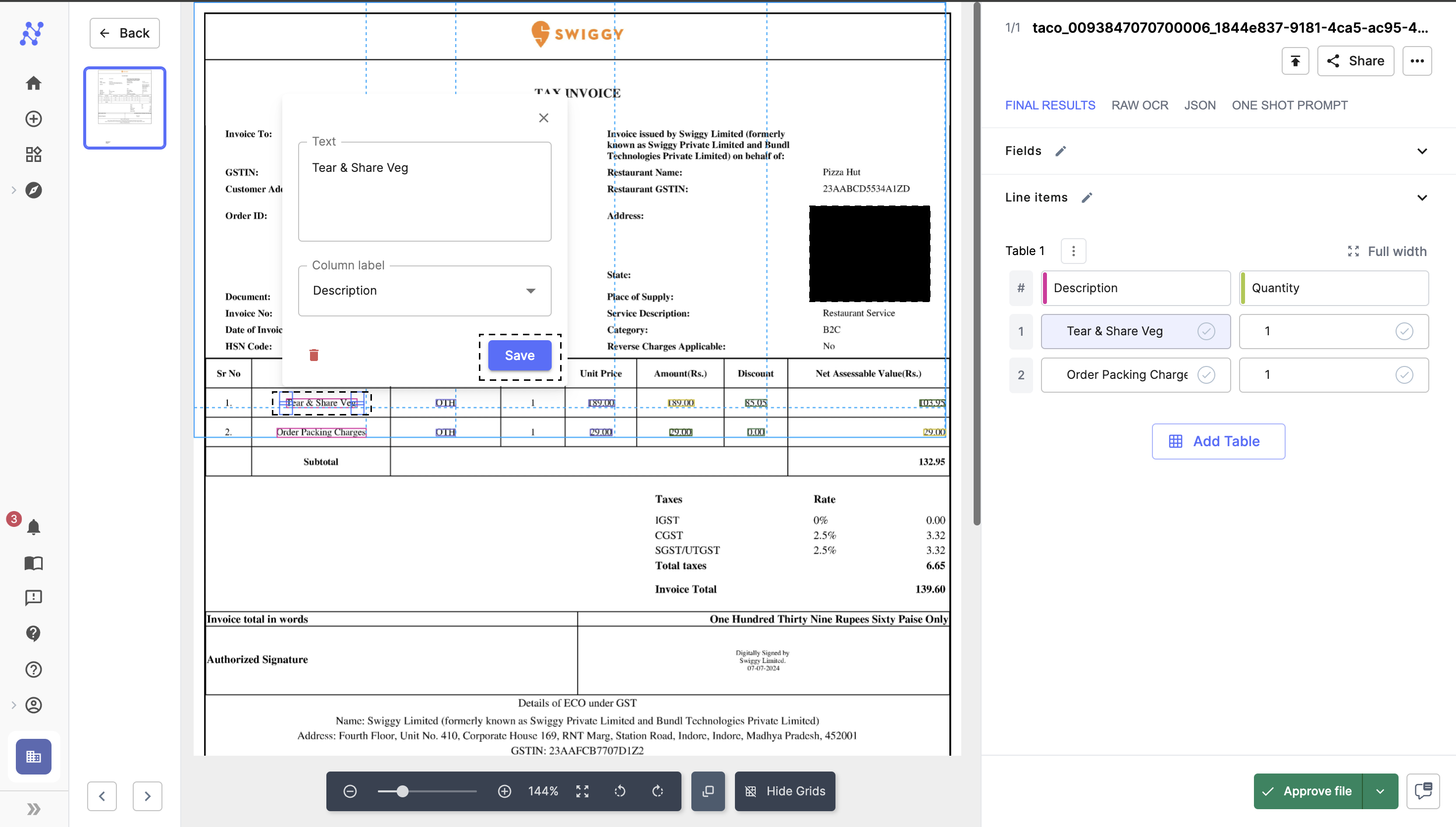
Make Corrections and Save Changes
2. Approve File to Train the Model
- Learning from Approved Images: The model learns exclusively from approved files. Approval is crucial for integrating these changes into the model’s training process.
- Approving the File: Once all necessary corrections are made, click the "Approve" button located at the bottom right of the interface to finalize the input for model training.
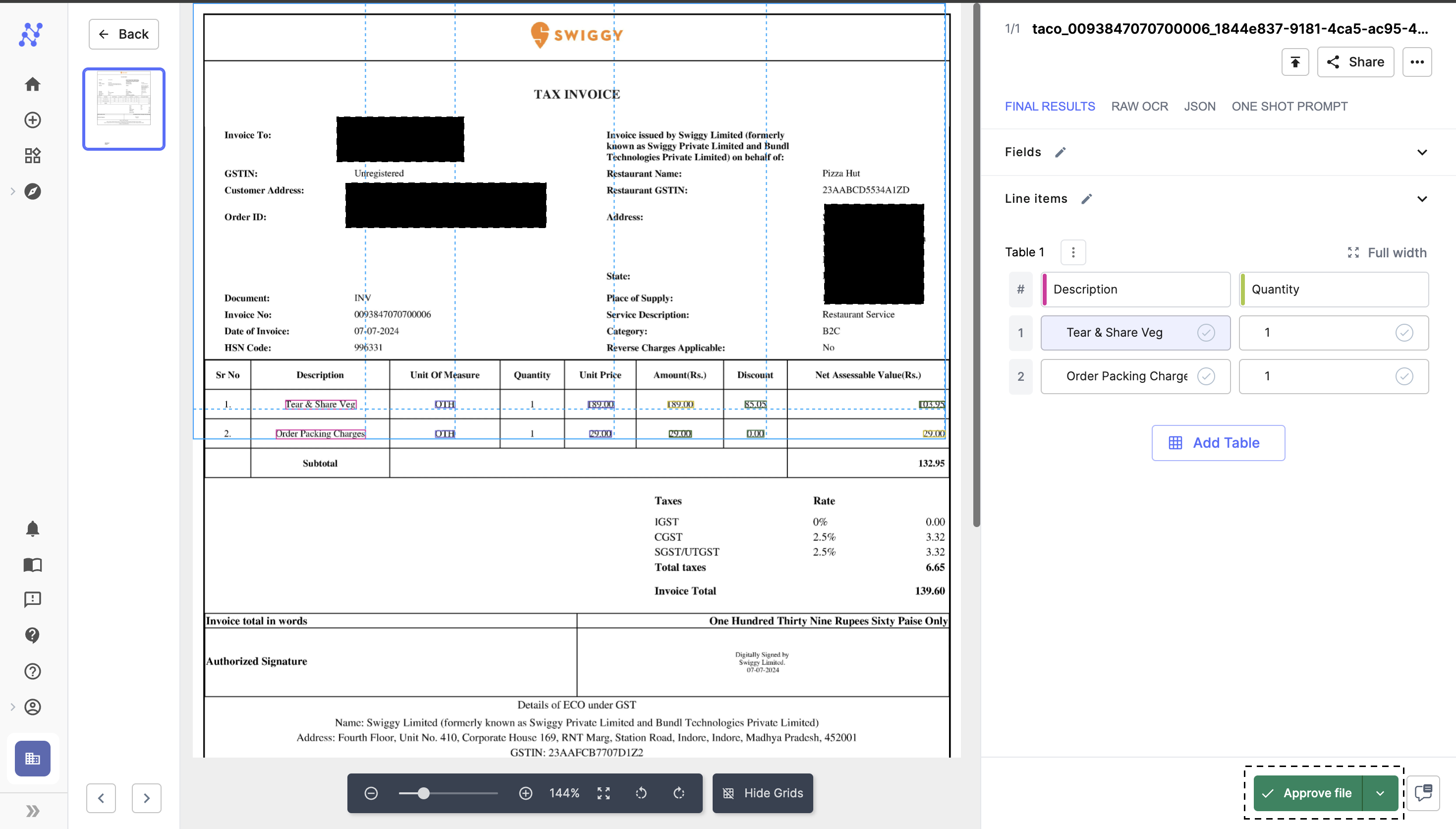
Approve File
Best Practices:
1. Annotations
- Consistency: Maintain uniform annotation conventions. For example, consistently label date and time under the same tag across all documents.
- Completeness: Ensure all images are fully annotated. In large datasets, prioritize complete annotations over partial ones.
- Selective Annotation: Annotate only the text needed, such as specific numbers or dates. The model will learn to recognize these within their textual context.
- Multiline Fields: Teach the model to recognize multiline fields like addresses, which may span several lines.
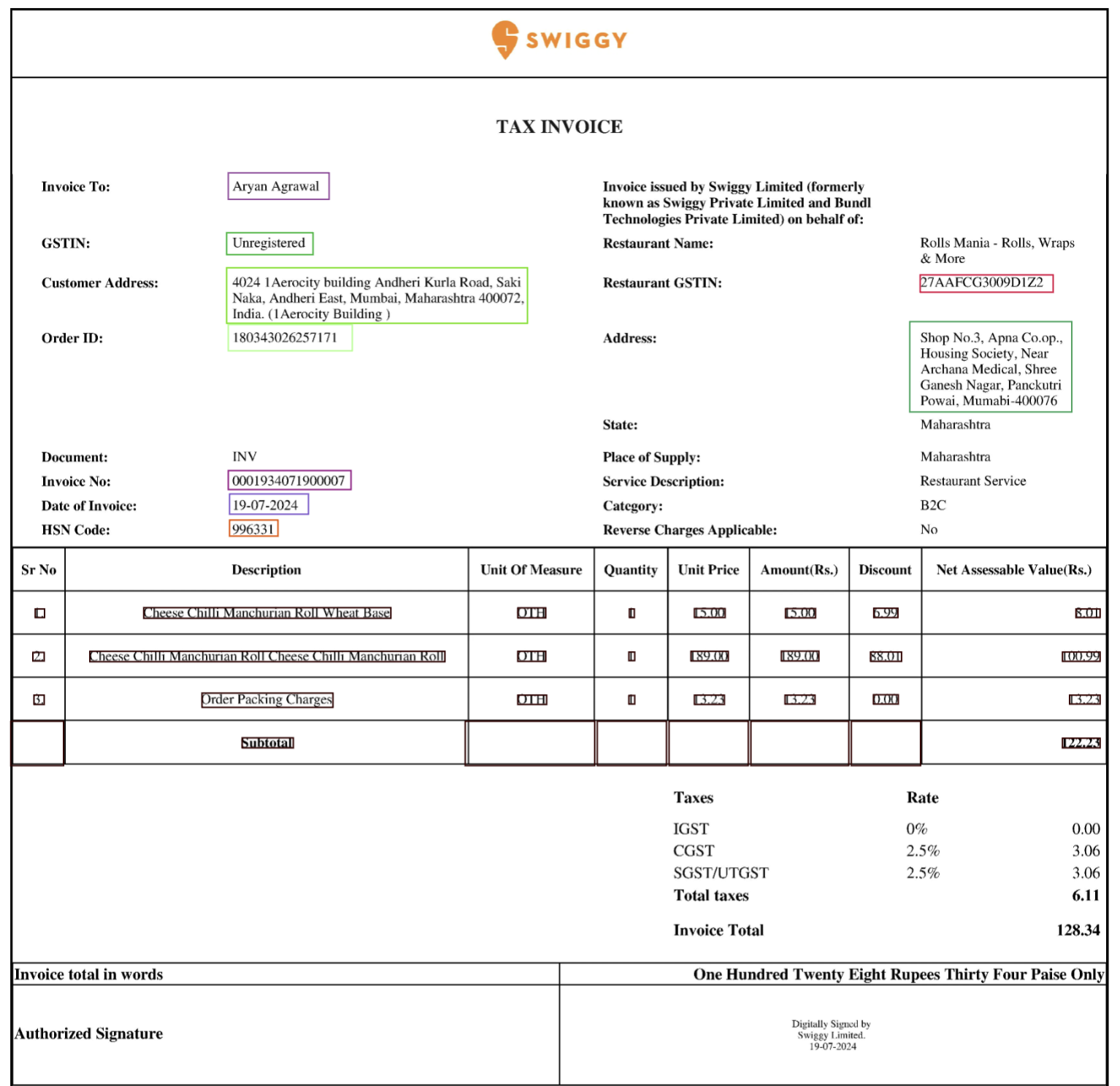
Annotate all the required labels
2. Quality of Data
- Readability: Ensure text within bounding boxes is clear enough for OCR recognition. Minor inaccuracies can be corrected during annotation.
- Avoid Blurry Images: Blurry images hinder OCR accuracy. It's preferable to use clear images to ensure reliable text recognition.

Blurred File
3. Quantity of Data
- More Data: Increasing the dataset size significantly enhances model accuracy. Train the model on all the formats you want to process.
- Dataset Diversity & Consistency: Train with diverse yet relevant images to the expected real applications. This consistency helps the model perform reliably across similar scenarios.
4. Field Description
- Be precise in setting up the field name:
- If you want the linkedin username from a resume, linkedin_username is a better choice than linkedin
- Use commonly used abbreviations only
- DOB is fine to use instead of Date of birth
- RMT is not fine to use instead of Road Motor Transportation
- Do not truncate words
- If a formal term exists for what you want, use that instead of describing what you want
- Use “given_name” instead of “first_and_middle_name”
- Be precise in giving field descriptions:
- Give explicit instructions on what the output of field should be
- Bad
- Field name: Need
- Field description : Customer has clearly defined Need to Buy the Product
- Good
- Field name: Product_Need
- Field description : Indicate 'Yes' if the customer has explicitly expressed intent to purchase the product, or 'No' if there is no such indication.
- Bad
- Give explicit instructions on what the output of field should be
5. Identifying new templates
-
A common challenge for users is identifying new templates. At Nanonets, this can be streamlined by configuring an approval stage to flag new templates. Any new template will enter this stage for review, while existing templates will bypass it. This ensures easy identification and management of new templates.
- Navigate to Workflow Setup:
Go to Workflow Setup -> Approvals and select the condition "Flag New Templates."
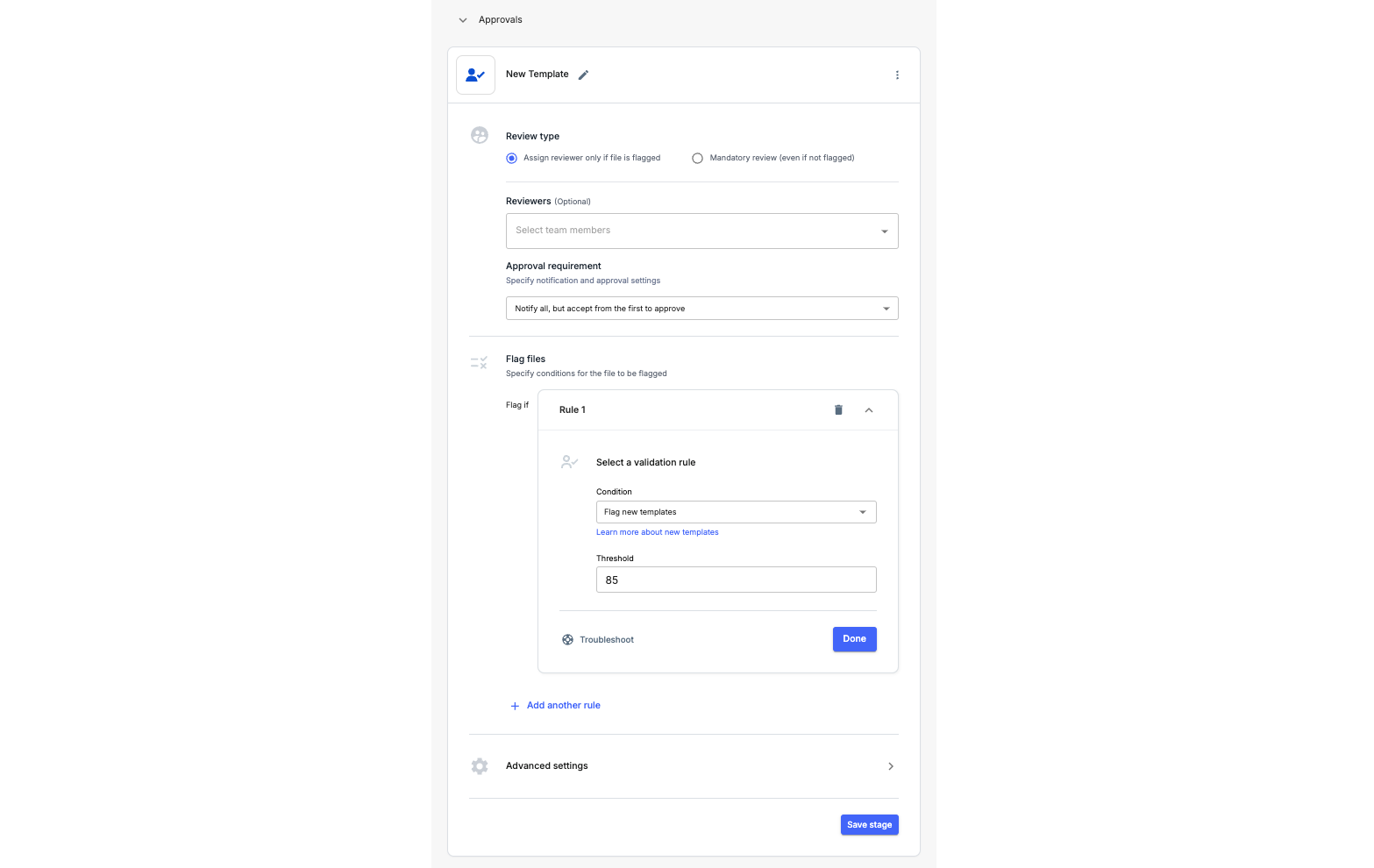
- Set a Threshold for Flagging New Templates:
- You can set a threshold value between 0 and 100. A threshold of 85 is recommended for optimal results.
- High threshold: More files will be flagged as new templates.
- Low threshold: Fewer files will be flagged as new templates.
- You can set a threshold value between 0 and 100. A threshold of 85 is recommended for optimal results.
- Review and Approve New Templates:
- When a new template is processed, the file will be flagged automatically for review. After reviewing the flagged file, you can approve it.
- Once approved, the AI will learn from your input and improve template identification in the future.
- Navigate to Workflow Setup:
What is the minimum resolution and file size of an image/PDF for OCR recognition to work well?
We recommend file sizes greater than 1000x1000 pixels or, in other words greater than 1000 pixels along both height and width dimensions.
For PDFs we internally convert it to images at 300 DPI.
While we can't comment on the file size as it would depend on the specific file format.
Updated 8 months ago