Confidence scores
Description
This doc describes how confidence scores work in predictions at Nanonets
Note: Confidence scores will be available on instant learning and zero training models in Q3 2024 (this date can change)
What do confidence scores represent?
Confidence scores represent the models confidence in its prediction
A higher confidence score represents a higher probability that the model is correctly predicting a field
Where do confidence scores come?
The confidence scores come in the API response for every bounding box/prediction. It comes in the score key for each prediction. It’s a float between 0-1
\[
{
"label": "Total_Amount",
"ocr_text": "615.00",
"score": 0.9854434, //this is the confidence score
"xmin": 1336,
"xmax": 1450,
"ymin": 3349,
"ymax": 3372,
"validation_status": "success",
"type": "field"
},
{
"label": "Net_Amount",
"ocr_text": "615.00",
"score": 0.5413188, //This is an example of a not so high confidence score
"xmin": 1335,
"xmax": 1450,
"ymin": 3265,
"ymax": 3288,
"validation_status": "success",
"type": "field"
},How can confidence scores be used?
- Validation rules can be setup to flag fields with a lower confidence score to go into manual review. This is the main usecase
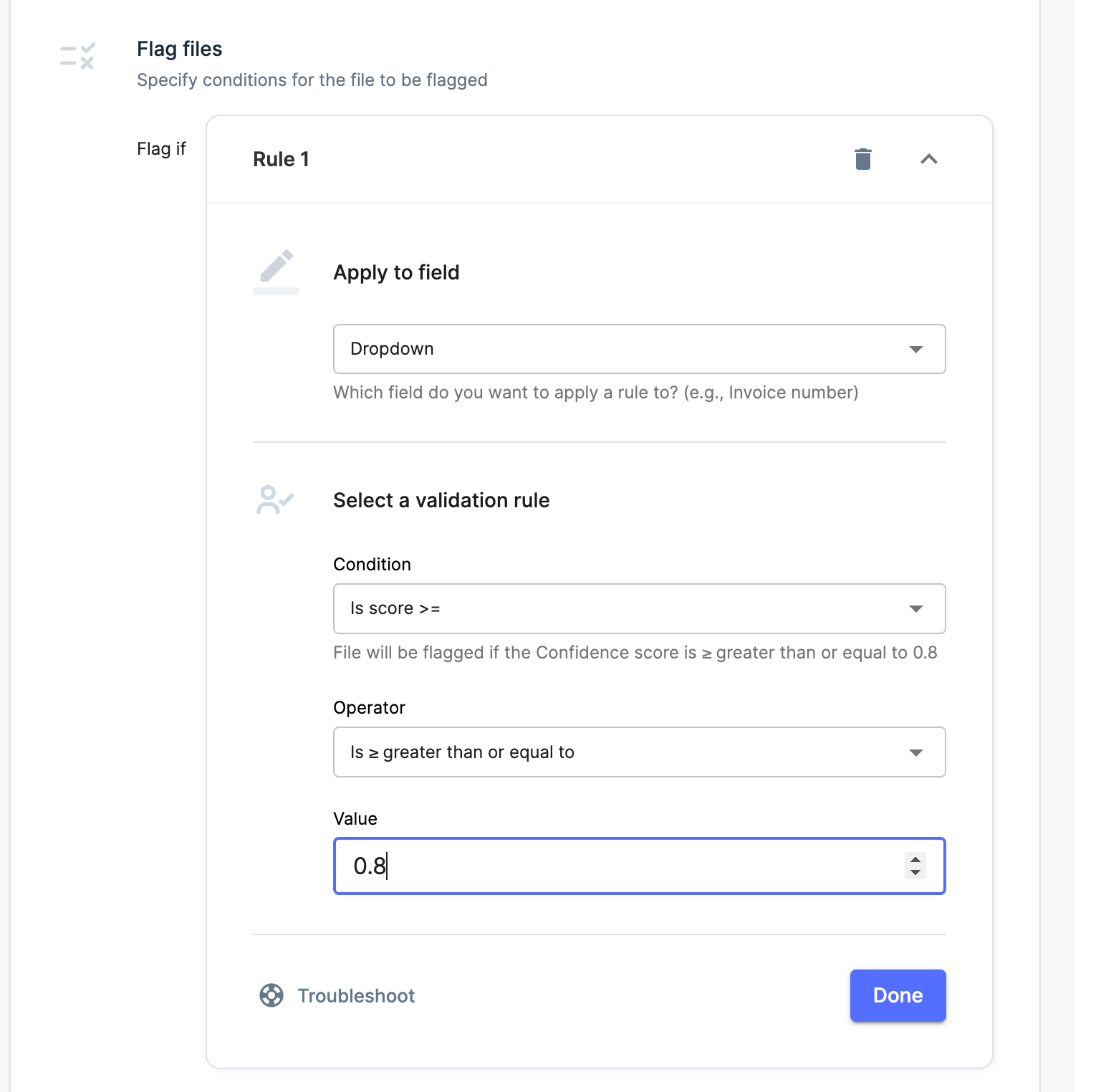
- The confidence scores can be combined to get an overall confidence score about the document
FAQ
- What is the correct threshold in setting confidence scores?
- We recommend setting it at around 0.8, in our experience this typically represents a recall and precision of 0.9 respectively. However in most cases scores need to be calibrated model wise to maximize precision and recall. This is mostly done by playing around and check what gets flagged.
- What is represented if the confidence score is 0.99?
- The answer to this can simply be that the a confidence score of 0.99 means that the model is extremely confident about the predicted value, and it very likely that the output is correct.
Updated about 1 year ago
Did this page help you?