Model Re-Training
Improved Model Training FlowAs of March 2025, the Improve Model training flow has been upgraded to offer greater flexibility and control over training file selection. Previously, all approved files were automatically used for training. Now, you can precisely select which files to include, providing enhanced control over your model's accuracy.
How This Helps
- Improve Training Data Quality – Not every approved file is necessarily reviewed, which can introduce incorrect data into training. Being selective ensures higher-quality data.
- Prevent Post-Processing Conflicts – Changes made in data actions or post-processing no longer interfere with model training.
- Train Specific Formats – You can focus on particular templates or formats to refine your model precisely where you need it.
Nanonets allows you to continually retrain your AI models to ensure optimal performance tailored to your data. Retraining enhances model accuracy and effectiveness based on your specific use case.
Managing Training Files
Model trains only on verified files:
-
Verified files located in AI Training → Training Files are used for model improvements.
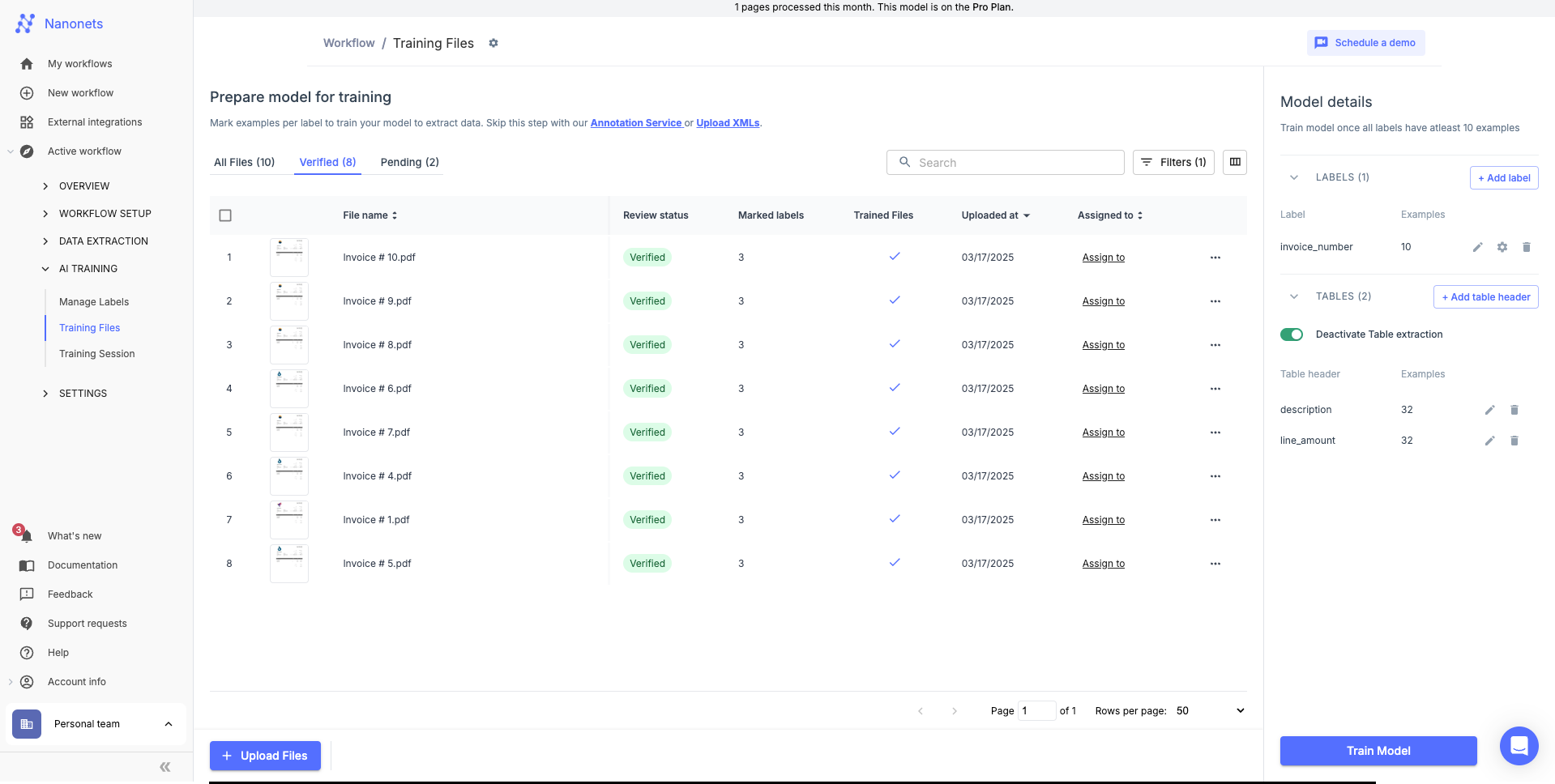
Only 8 verified files will be used for learning. The 2 pending files are ignored.
-
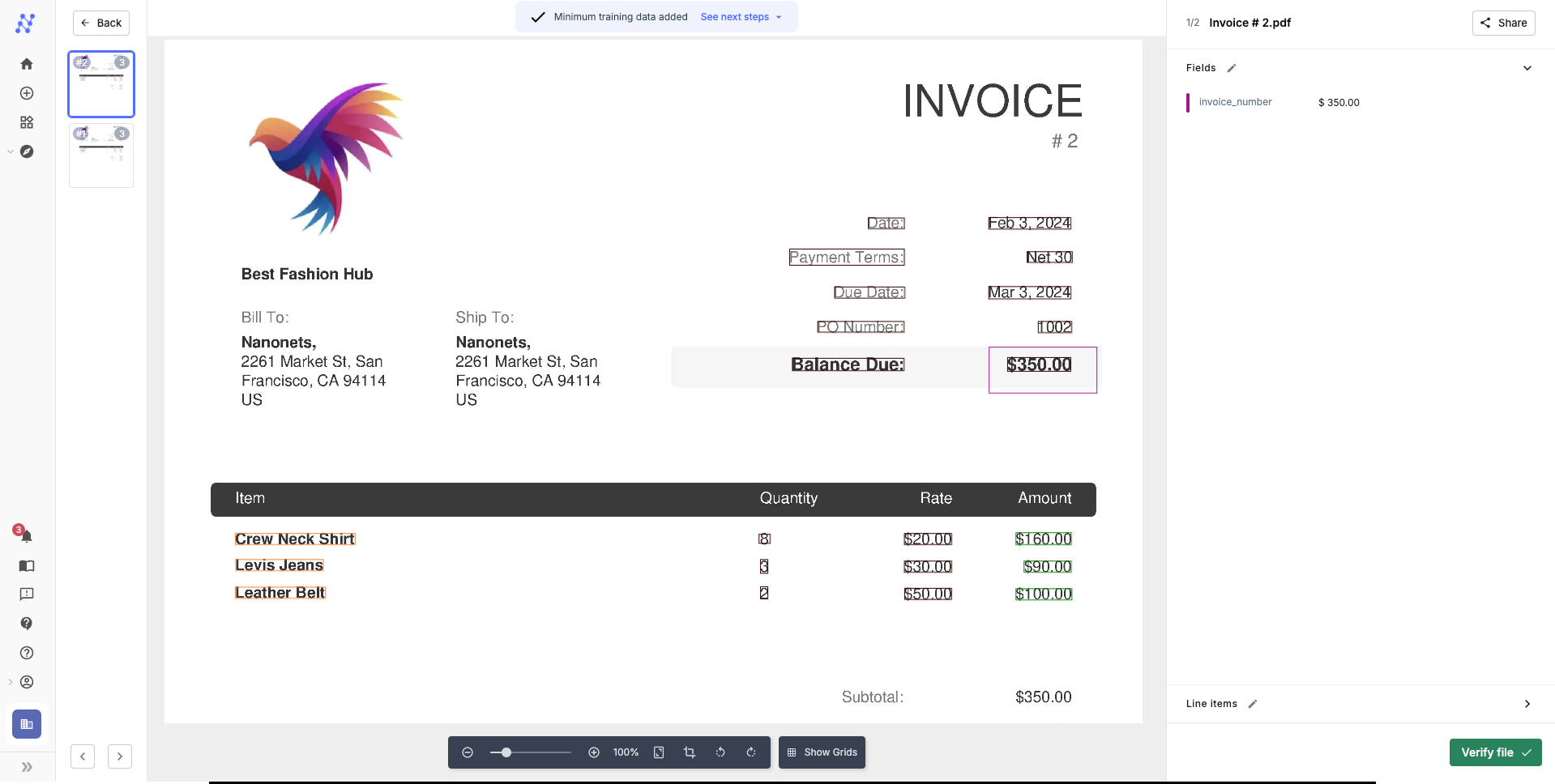
You can verify a file by opening it and clicking on Verify file
-
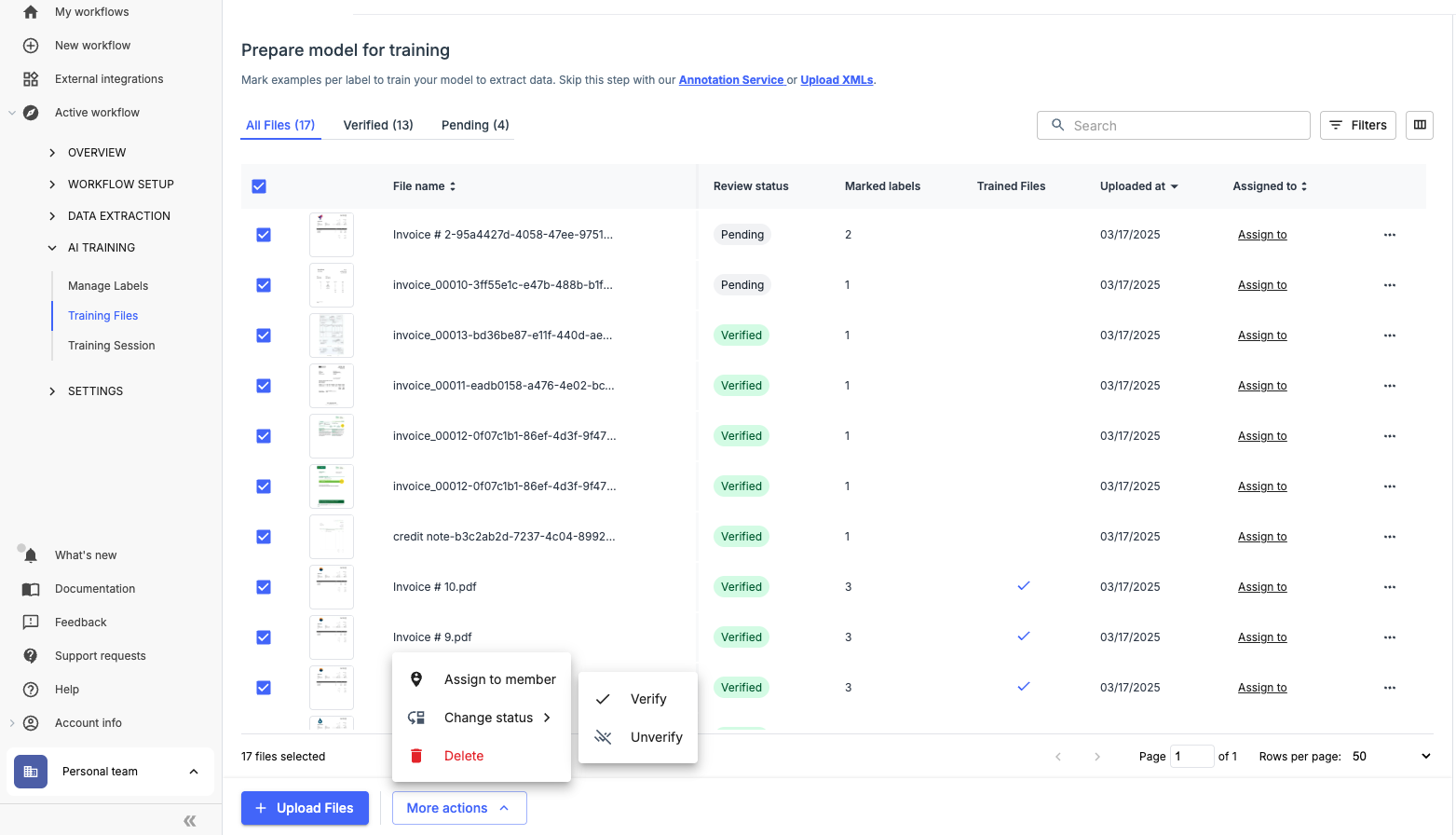
You can also select multiple files and verify in bulk
Adding files to training:
-
Automatic Training:
-
Enable "Auto-training" to automatically move approved files to the Training Files section.
-
Enable "Auto-training verification" to automatically verify and utilize these files for training.
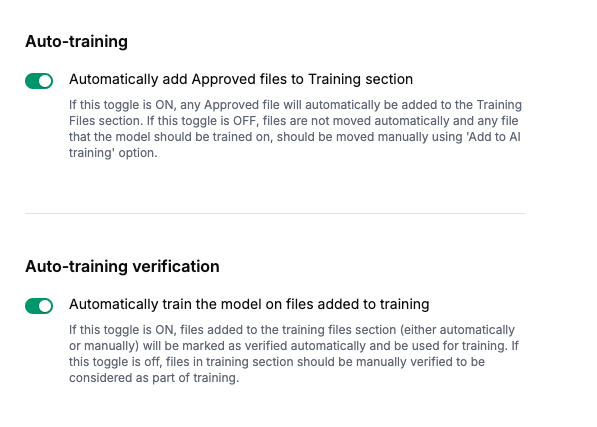
Use Automatic Training only if approved files are 100% correct and doubly verifiedAutomatically adding approved files to training usually results in errors in Training Data. Training data needs to meet higher standards of quality as a few mistakes in training data can cause large errors in processing files. If you are unsure, it is recommended to add files manually instead.
-
-
Manual (recommended):
-
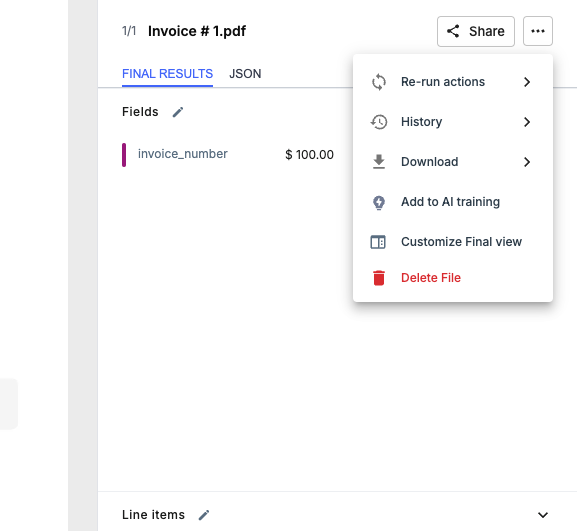
Manually select individual files from Extract Data and choose "Add to AI Training".
-
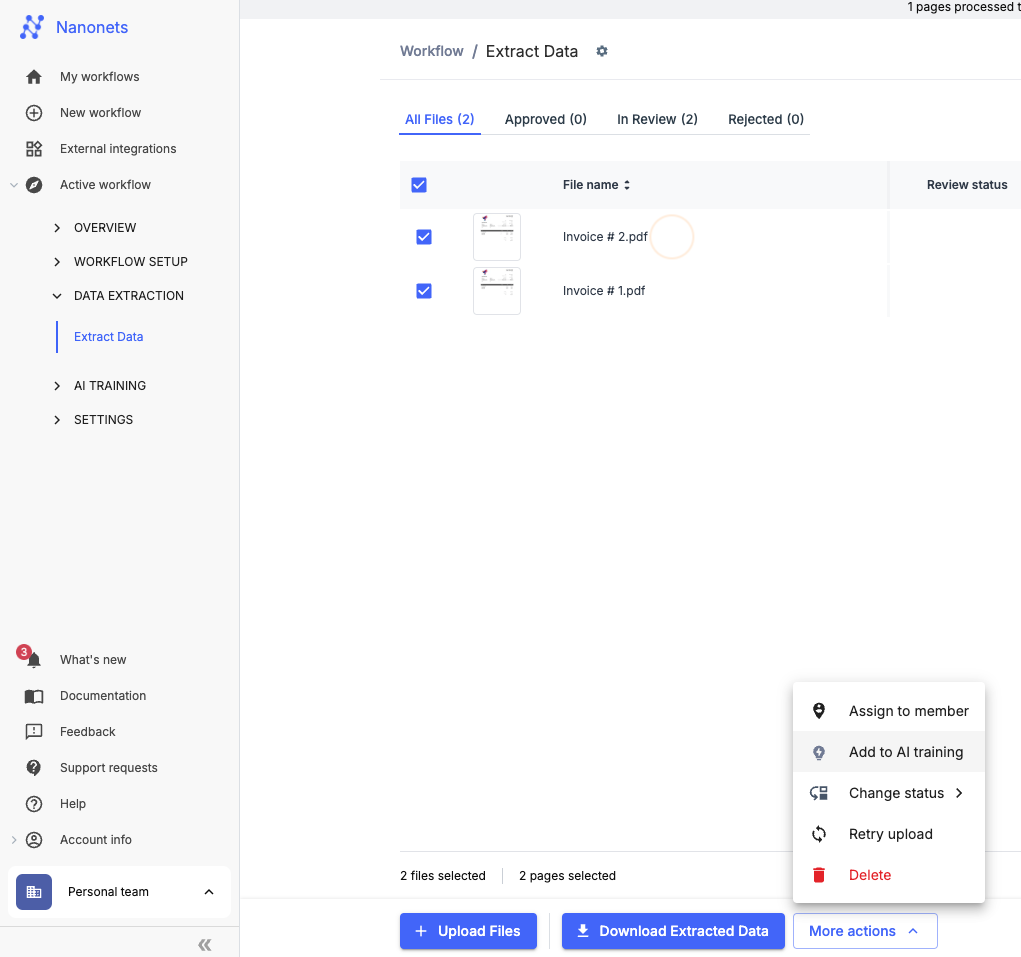
Add multiple files simultaneously by selecting files and navigating to More Actions → Add to AI Training.
-
Preventing Post Processing Conflicts
Many models are configured to process multi-page files at the page level, then consolidate results by using “Keep only one instance” for certain fields. For example, suppose you have a five-page invoice where seller_name appears on each page, but you only keep it annotated on one page after approval. This leads to inconsistent information for the AI: it registers a seller_name field on one page, yet the same field goes completely unannotated on the remaining pages—even though it’s actually present. As a result, the AI gets confused and overall accuracy declines.
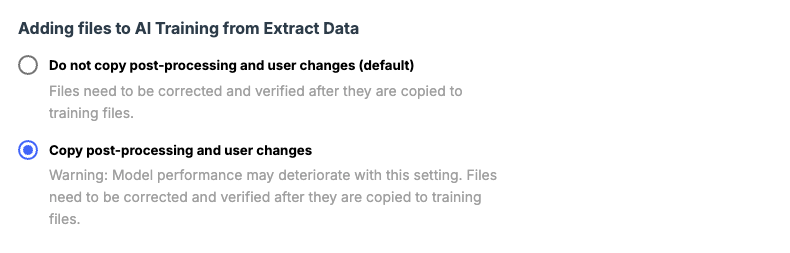
To avoid this, every instance of a field should be annotated on every page where it appears. Since re-adding deleted boxes and annotations to multi-page files can be time-consuming, we provide a model setting that allows you to ignore user changes when transferring files from “Extract Data” to “AI Training”. By selecting “Do not copy post-processing and user changes” any fields removed during consolidation are restored for training. However, any user-made corrections (like bounding box adjustments) won’t be copied over, so you’ll need to re-verify these files in the AI Training section.
While it might sound like you’ll be annotating files twice, you can minimize extra work by copying/correcting only new templates or files where the AI frequently makes mistakes. This approach keeps your training data both high-quality and manageable, boosting model accuracy without overwhelming your workflow.
Starting Training Session
- To initiate manual training, click on the "Train Model" button within the Training section.
- Verified files located in AI Training → Training Files are utilized for training.
Improve Model through Extract Data is no longer supported for model training
Best Practices
- Ensure all verified training files are correctly annotated with correct bounding boxes.
- Generally, training data quality reduces as number of training files increases. Its more useful to have lesser but 100% correct training data, than have a lot of training data but with errors.
Updated about 1 year ago